
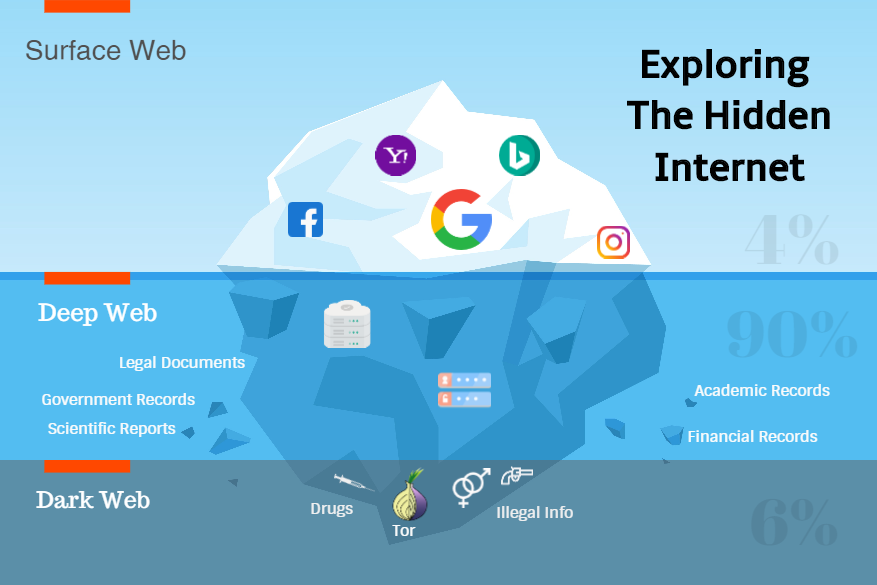
Search engines are the main source for discovering new sites when looking for information. But the search engines have a limit, because they manage to discover only a very small part of what is called the Internet. Basically, through searches, we only scratch the surface of the Internet.
Most of the Internet remains hidden because it is so intentional. The Internet is like an iceberg that floats and leaves only 10% of its entire volume. The Internet that regular users access (blogs, portals, news sources, video sites, etc.) is called Surface Web or Clear Web. Everything is in sight here and sites can be accessed through search engines.
The unseen part of the internet is called the Deep Web and it appeard under the concept of onion routing in 1995 when the US Army tryed to communicate with those abroad, without being detected. In 2004 the TOR project was made public and two years later, the service that works today and which represents a gateway to the Deep Web appeared. Nowadays the Deep Web contains databases from companies and state institutions. It is the databases behind the sites or internal databases that are very massive and most often contain confidential information. Search engine crawlers have prohibited access here and cannot discover new information. Among the most popular sites on the Dark Web are Silk Road, Agora, and Evolution.
The general concept is that the Dark Web does not gather exactly the right things. It is true that criminals take advantage of this hidden network to carry on their activity. However, there is also a good part. Here, information that would endanger those who publish it if the source were found can be shared anonymously. It is the case of WikiLeaks that has found this area of the web an opportunity to reveal certain information. There is even a program called SecureDrop that is integrated with Tor services and offers anonymity for those eager to publish sensitive information.
Sanda Spinu
Master 2 Cyberjustice – promotion 2018-2019

